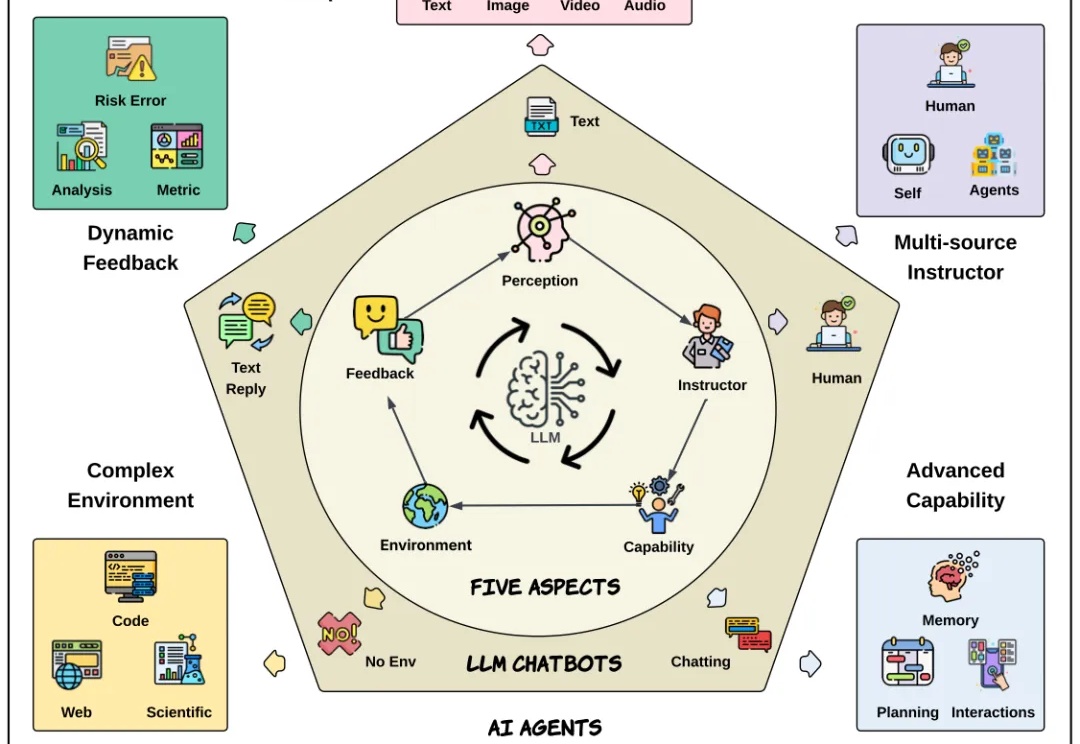
AI Agent、传统聊天机器人有何区别?如何评测?这篇30页综述讲明白了
AI Agent、传统聊天机器人有何区别?如何评测?这篇30页综述讲明白了自从 Transformer 问世,NLP 领域发生了颠覆性变化。大语言模型极大提升了文本理解与生成能力,成为现代 AI 系统的基础。而今,AI 正不断向前,具备自主决策和复杂交互能力的新一代 AI Agent 也正加速崛起。
来自主题: AI技术研报
6679 点击 2025-07-03 10:31
 搜索
搜索
自从 Transformer 问世,NLP 领域发生了颠覆性变化。大语言模型极大提升了文本理解与生成能力,成为现代 AI 系统的基础。而今,AI 正不断向前,具备自主决策和复杂交互能力的新一代 AI Agent 也正加速崛起。

在 AI 时代的浪潮下,顶尖人才影响力空前高涨,其地位更被市场推升至了前所未有的高度。无论是谷歌 Transformer 论文八子,还是从 OpenAI 出走的科学家,他们要么自立门户,拿到亿级投资、百亿级估值,或者跳槽到他处,凭己之力拉近企业间的技术代差甚至影响竞争格局。
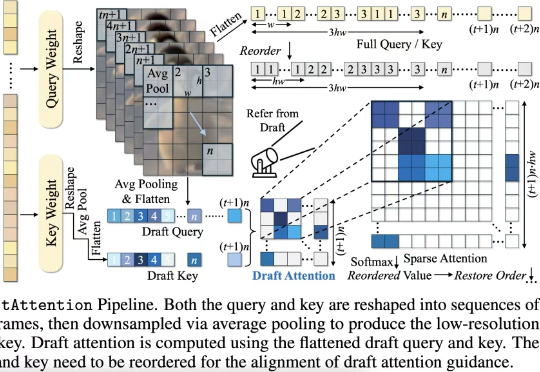
在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。
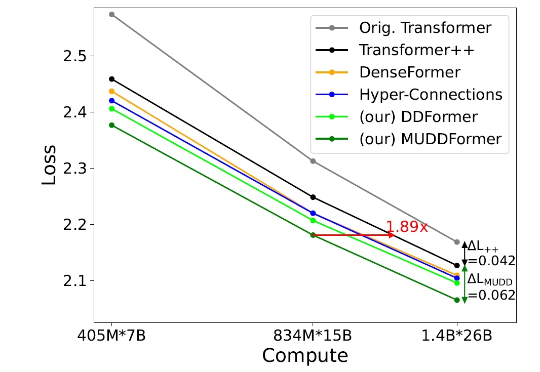
但在当今的深度 Transformer LLMs 中仍有其局限性,限制了信息在跨层间的高效传递。 彩云科技与北京邮电大学近期联合提出了一个简单有效的残差连接替代:多路动态稠密连接(MUltiway Dynamic Dense (MUDD) connection),大幅度提高了 Transformer 跨层信息传递的效率。
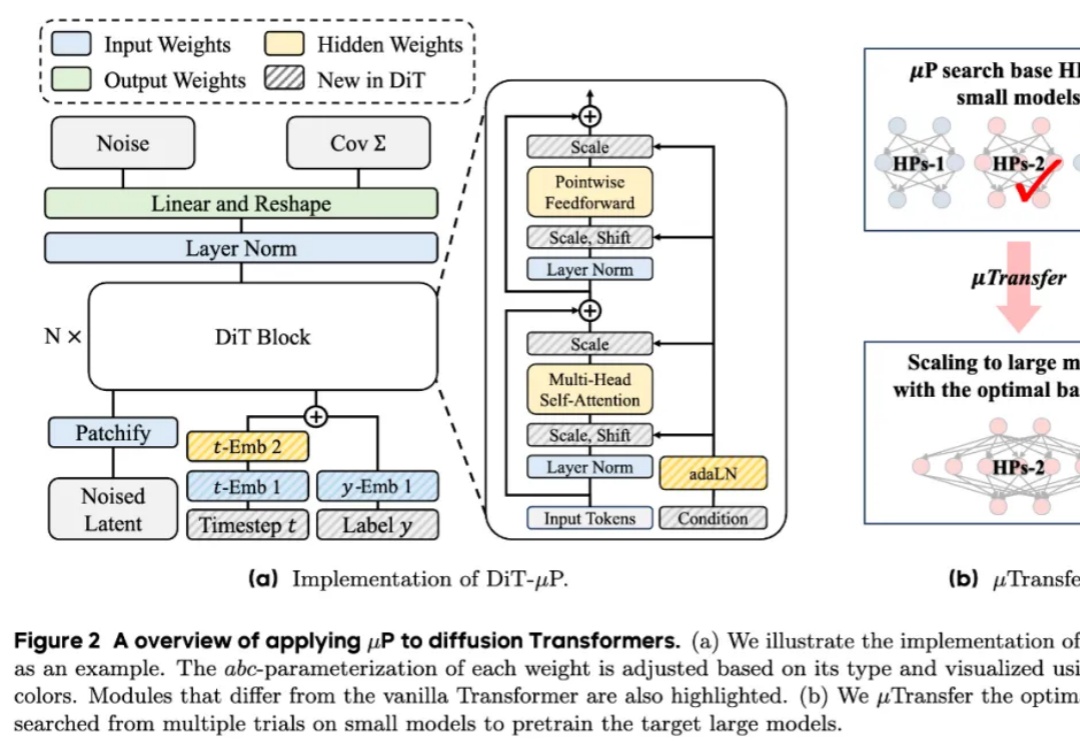
近年来,diffusion Transformers已经成为了现代视觉生成模型的主干网络。随着数据量和任务复杂度的进一步增加,diffusion Transformers的规模也在快速增长。然而在模型进一步扩大的过程中,如何调得较好的超参(如学习率)已经成为了一个巨大的问题,阻碍了大规模diffusion Transformers释放其全部的潜能。
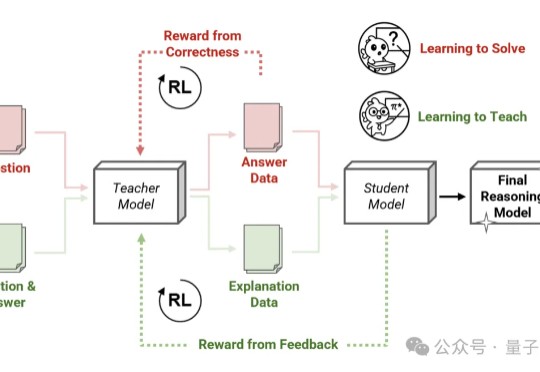
Thinking模式当道,教师模型也该学会“启发式”教学了—— 由Transformer作者之一Llion Jones创立的明星AI公司Sakana AI,带着他们的新方法来了!

本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。
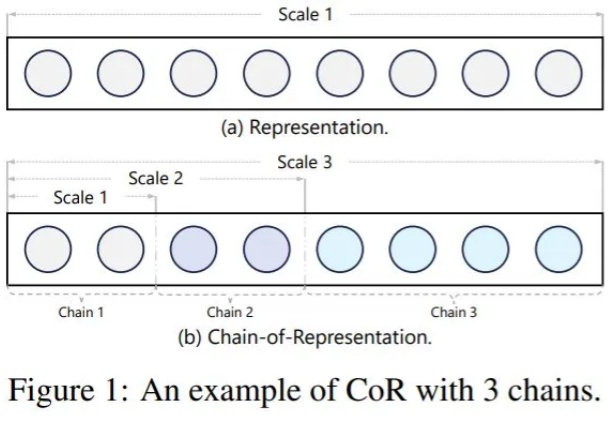
随着大语言模型 (LLM) 的出现,扩展 Transformer 架构已被视为彻底改变现有 AI 格局并在众多不同任务中取得最佳性能的有利途径。因此,无论是在工业界还是学术界,探索如何扩展 Transformer 模型日益成为一种趋势。
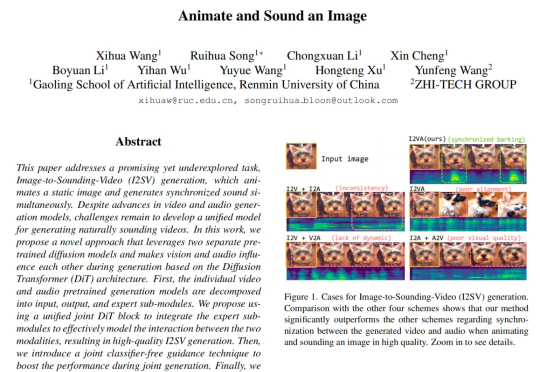
来自中国人民大学高瓴人工智能学院与值得买科技 AI 团队在 CVPR 2025 会议上发表了一项新工作,首次提出了一种从静态图像直接生成同步音视频内容的生成框架。其核心设计 JointDiT(Joint Diffusion Transformer)框架实现了图像 → 动态视频 + 声音的高质量联合生成。
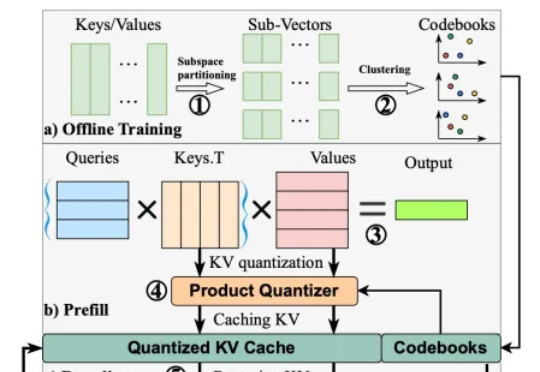
在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。